What is vLLM-DeepSeek-R1-Distill
Knowledge distillation technology can transfer the reasoning capabilities of large models to smaller models, significantly enhancing the performance of compact models. By using reasoning data generated through DeepSeek-R1, the DeepSeek team has fine-tuned several commonly used small dense models and open-sourced the DeepSeek-R1-Distill series of distilled models based on Qwen2.5 and Llama3 architectures, covering 1.5B, 7B, 8B, 14B, 32B, and 70B parameter scales. Detailed model names and recommended configurations:
| Model Name | Recommended Configuration |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1x RTX 4090 |
| DeepSeek-R1-Distill-Qwen-7B | 1x RTX 4090 |
| DeepSeek-R1-Distill-Llama-8B | 1x RTX 4090 |
| DeepSeek-R1-Distill-Qwen-14B | 2x RTX 4090 |
| DeepSeek-R1-Distill-Qwen-32B | 4x RTX 4090 |
| DeepSeek-R1-Distill-Llama-70B | 8x RTX 4090 |
Advantages of Distilled Models:
- Performance Enhancement::Maintains comparable performance to original models while reducing parameter counts. Distilled small models outperform reinforcement learning (RL)-trained counterparts in reasoning tasks.
- Resource Efficiency::Compact models are ideal for hardware with limited resources (single/multi-GPU setups), significantly improving inference speed and reducing GPU memory consumption.
vLLM-DeepSeek-R1-Distill integrates DeepSeek-R1-Distill models with the vLLM framework, which optimizes inference performance for large language models through efficient GPU memory management and distributed inference support, substantially boosting operational efficiency.
How to Run vLLM-DeepSeek-R1-Distill
Starting vLLM Service
The pre-configured environment requires no additional setup. Launch the service with a single command!
After initializing your instance, execute the following command in JupyterLab:
# Start vLLM API service
vllm serve <model_path> --port 8000Example for DeepSeek-R1-Distill-Qwen-7B::
# DeepSeek-R1-Distill-Qwen-7B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8000 --max-model-len 65536When you see the output below in the console, the service is successfully running:

The service uses port 8000 by default. Enable this port in your firewall for public access.
Recommended GPU Configurations & Launch Commands
For 1x RTX 4090
# DeepSeek-R1-Distill-Qwen-1.5B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --port 8000# DeepSeek-R1-Distill-Qwen-7B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8000 --max-model-len 65536# DeepSeek-R1-Distill-Llama-8B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Llama-8B --port 8000 --max-model-len 17984For 2x RTX 4090:
# DeepSeek-R1-Distill-Qwen-14B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --port 8000 -tp 2 --max-model-len 59968For 4x RTX 4090:
# DeepSeek-R1-Distill-Qwen-32B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --port 8000 -tp 4 --max-model-len 65168For 8x RTX 4090:
# DeepSeek-R1-Distill-Llama-70B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Llama-70B --port 8000 -tp 8 --max-model-len 88048Running Examples
After starting the vLLM service (do not terminate the process), create a new Launcher via the top-left "+" button:
Open a new Terminal from the Launcher::
In the workspace/ directory, run test.py to validate the model. This script requests the model to generate a 200-word essay:
`
python test.pyView the full code in test.py via
JupyterLab.
After execution, the console will display the model's response (see below). The <reasoning> tags enclose intermediate steps, while the final output appears outside these tags:

The DeepSeek-R1-Distill series model is a large-scale inference language model, so its reply content has two parts, among which <think> and </think> wrap the inference process of the output of the large model, and the final output content of the large model outside the label is the output result we want.
Benchmark Scores & Usage Scenarios
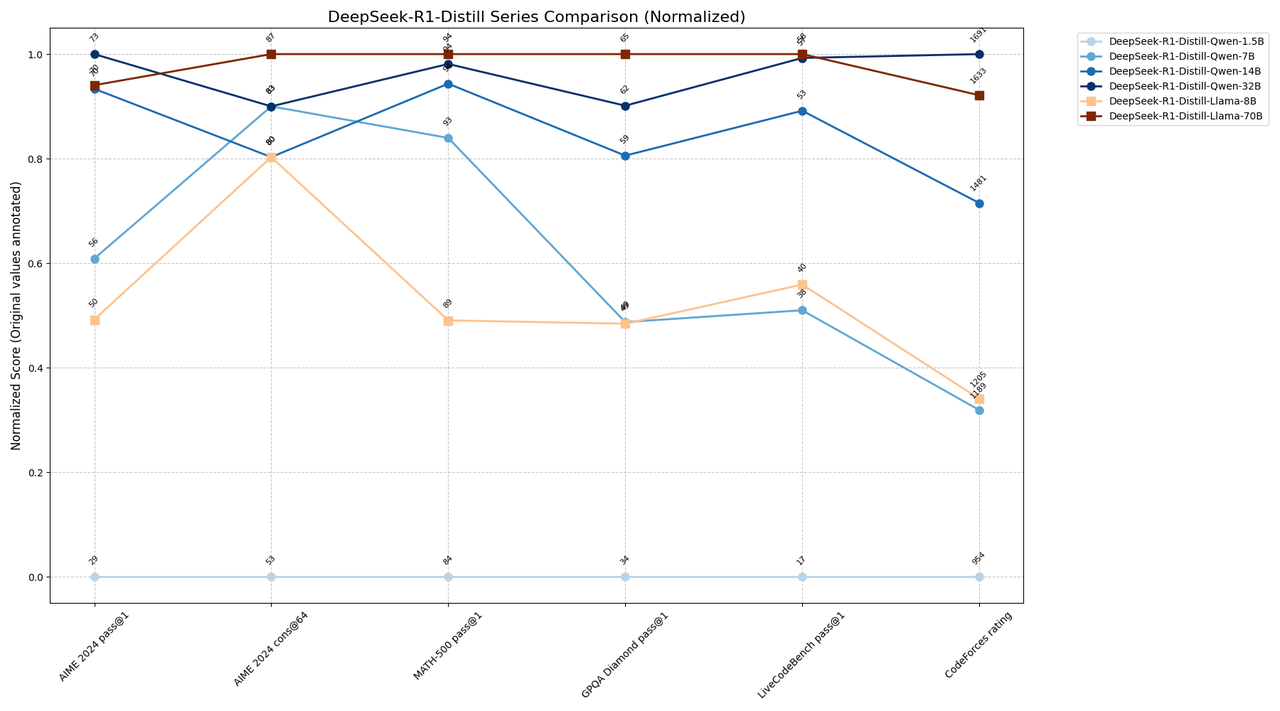
Recommended Use Cases: 1.Resource-constrained scenarios: Qwen-7B (1189 CF / 92.8 MATH) 2.Balanced performance needs: Qwen-14B (1481 CF / 93.9 MATH) 3.High-performance demands: Qwen-32B or Llama-70B (CF 1600+ / MATH 94%+) 4.Quality-critical tasks: Llama-70B (GPQA 65.2 / AIME cons@64 86.7)